As we step into the new year, we reflect on the progress, challenges, and collaborations that have defined our journey in 2023. The loss of our founder-director, Shashank Srinivasan, has been a profound moment for our organisation. Despite the challenges, we remain committed to our mission of amplifying conservation impact and express gratitude to our collaborators, donors, and well-wishers for their continued support.

TfW core-team in discussion, Jan 2023.
We commenced the year with an in-person team meeting to discuss our objectives and goals for the first quarter.
At the end of the week, we made simultaneous in-person presentations. One was at Ganpat Parsekar College, Arambol as part of a state-level workshop supported by the Directorate of Higher Education, Goa. We spoke to students about the use of technology for conservation. The other was a presentation on the transmission line through Mollem at the inaugural meeting of the Goa Development Group at a seminar on Goa's economy and society, hosted by the Goa Institute of Management.

Nandini Mehrotra presenting on the use of conservation technology.

TfW with Dr. Nandini Velho in Mollem National Park.
In the following week, we undertook our first field trip of the year to Bhagwan Mahaveer Sanctuary and Mollem National Park. We looked at linear infrastructure features cutting through the park.

Alex identifying boundaries of the forest land in Mhadei.

TfW mentoring students of Srishti for a studio. Picture courtesy of Himanshi Parmar.
In mid-January, we visited Alex Carpenter and Cristina Toledo near Mhadei Wildlife Sanctuary in Goa, where they focus on restoring private forest land. Here we initiated our collaboration of experimenting with a combination of ground, UAV and satellite-based data to aid restoration activities.
Also in January, we mentored students at Srishti Institute of Art, Design and Technology for a studio on environmental design taught by Himanshi Parmar.

Nandini Mehrotra in discussion with the CILS5 cohort. Picture courtesy of Pakhi Das.
In February, we took part in the Fifth Central Indian Landscape Symposium (CILS5) near Kanha National Park. Hosted by the Network for Conserving Central India (NCCI), this acts as a platform for stakeholders to discuss conservation challenges in the region. Nandini Mehrotra, our Programme Manager, attended the conference and held an interactive session on the use of technology for wildlife and environmental conservation.

TfW conducting field-work in Bihar.
We have been working with Wildlife Conservation Trust, India (WCT) exploring the use of UAVs for the study and conservation of Gangetic river dolphins and gharials. In February, we successfully completed our second field trip to Bihar with WCT, conducting aerial surveys of behaviour and population estimation of these vulnerable species.

Introducing Bihar FD to the use of UAVs for conservation.
Following the field surveys, both organisations jointly organised a comprehensive day-long training workshop for the Bihar Forest Department. The workshop, centred on monitoring threats to river-floodplain wildlife in the Gandak River, served to enhance the skills and knowledge of frontline forest staff.

Team viewing live-stream of olive ridleys through the drone-controller.
Each year, hundreds of thousands of olive ridley turtles nest on the beaches of Odisha before returning to the sea. In March, we conducted fieldwork in Odisha to assess the feasibility of using drones for studying near-shore olive ridley turtle aggregations, as part of a three-way collaboration with WWF-India and Dakshin Foundation.
During a joint field survey we captured aerial footage revealing these turtles as small white dots off the coast of the Rushikulya mass nesting beach. Additionally, we gathered aerial video-transects of near-shore turtle aggregations and generated orthomosaic maps of nesting beaches.
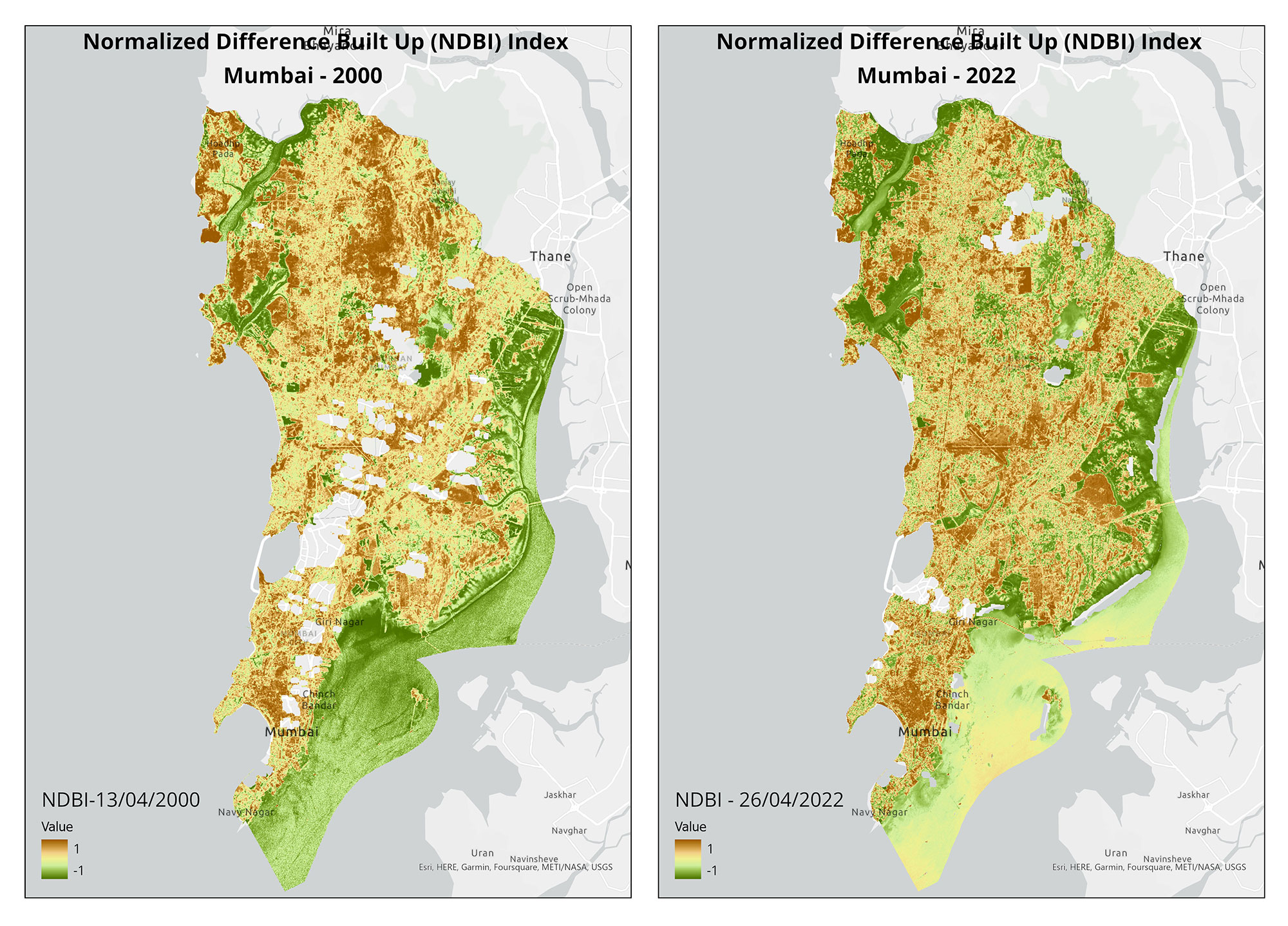
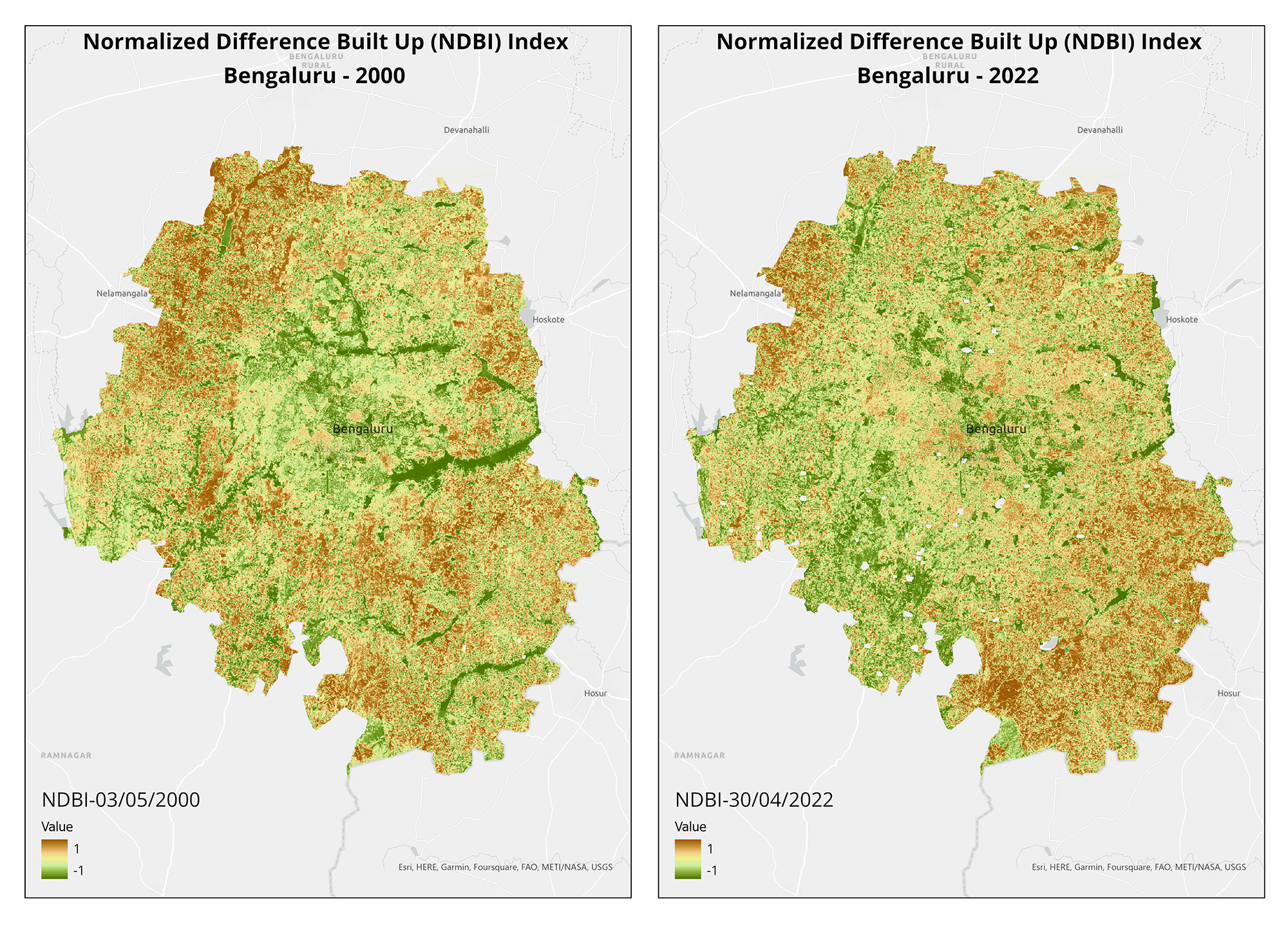
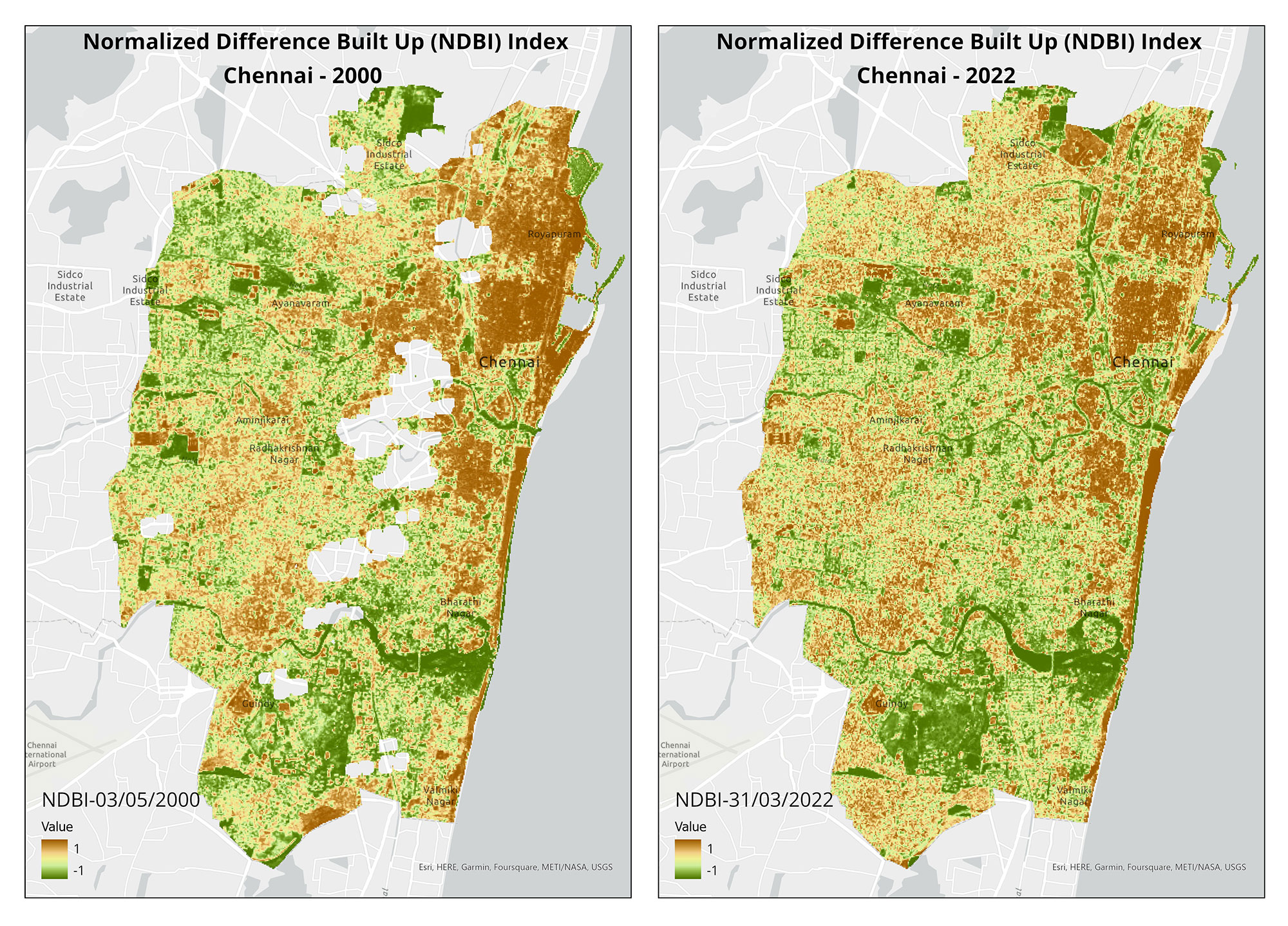
During the first weeks of March, Goa's Western Ghats experienced intense fires. We created burn scar maps to identify affected forest areas, to inform future restoration projects. Our conservation geographer, Sravanthi Mopati, detailed the steps to create these maps in a blog as well.
In March, we also crafted a story map explaining the linear infrastructure projects proposed through Mollem in 2020 and summarising updates on the proposed projects since then.

Aditi Ramchiary presenting to high school students on TfW’s work.
We also spoke to high school students about our work and the use of technology for conservation on an educational trip organised by Journeys with Meaning.
Towards the end of March, the core-team gathered in person to review the first quarter, assess ongoing tasks, and plan for the upcoming months.
Also during this month, we unveiled the illustration created by Aashti Miller for TfW. Highlighting some of the different species that we have had the privilege to work with, the illustration conveys the nature of our work towards creating meaningful impact, by the use of appropriate technology for the conservation of wildlife and the environment.
We conducted phase one of an internal capacity building workshop on the use of vector design tools for cartography, and refined our spatial analysis workflow.
In April, we made the most of our time away from the field by analysing data, documenting methodologies, and creating communication material from our field work.

Illustration by Aashti Miller.

Artwork by Svabhu Kohli.
On 22nd April, 2023 we faced an unexpected and heart-wrenching loss with the sudden passing of our founder-director, Shashank Srinivasan. His vision for conservation, with his leadership, passion, and conviction are the driving forces behind this organisation's existence. While in this profound grief, the outpouring of support from all quarters helped us regain stability in the ensuing months.

TfW in Mhadei, May 2023.

TfW core-team, June 2023. Picture courtesy of Supriya Roychoudhury.
For our final field trip before the monsoon, we revisited Alex and Cristina's restoration project near Mhadei Wildlife Sanctuary. We used our UAVs to look at the effects of recent forest fires, the detrimental impact of invasive species and map parts of their plot as pilot sites for targeted assisted regeneration as well as control sites.
Later in May, we gathered in person at a co-working space in Goa to work together as a team on alternative days of the week. We also completed the second phase of our counter-mapping work with our collaborators for NID Ahmedabad.

Map output from the counter-mapping exercise.
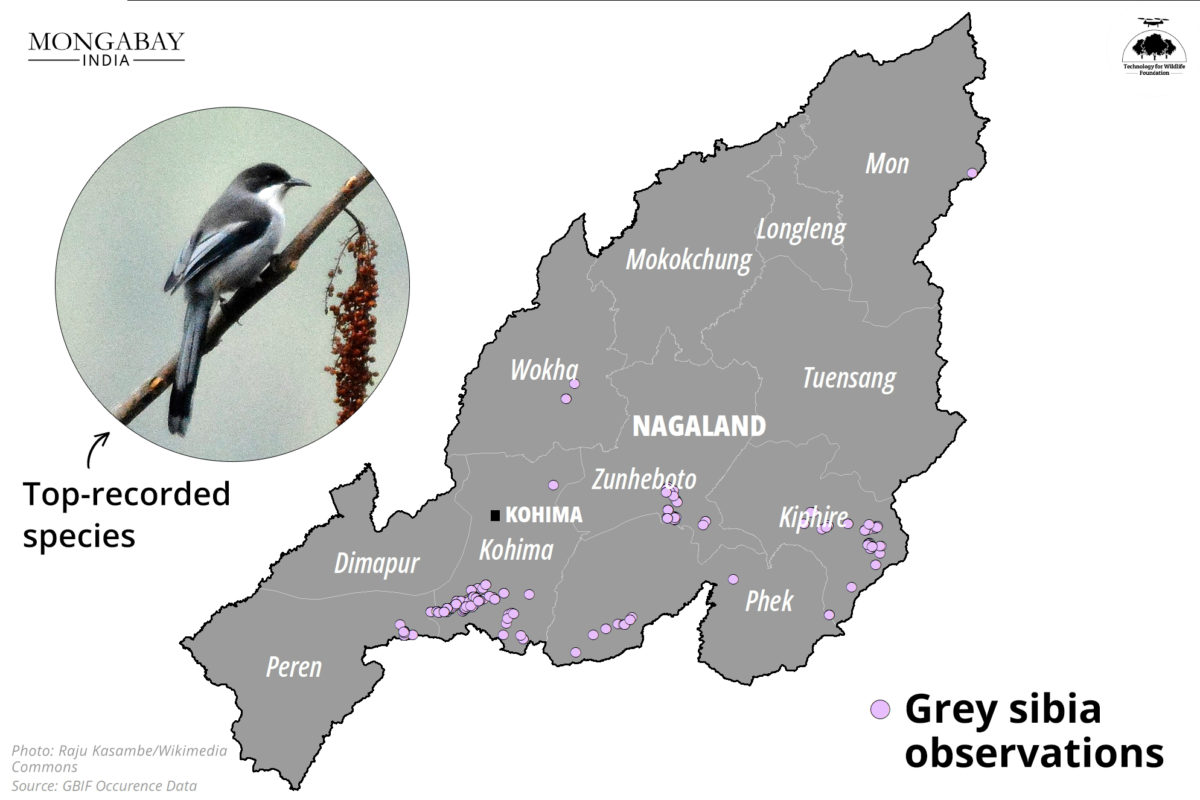
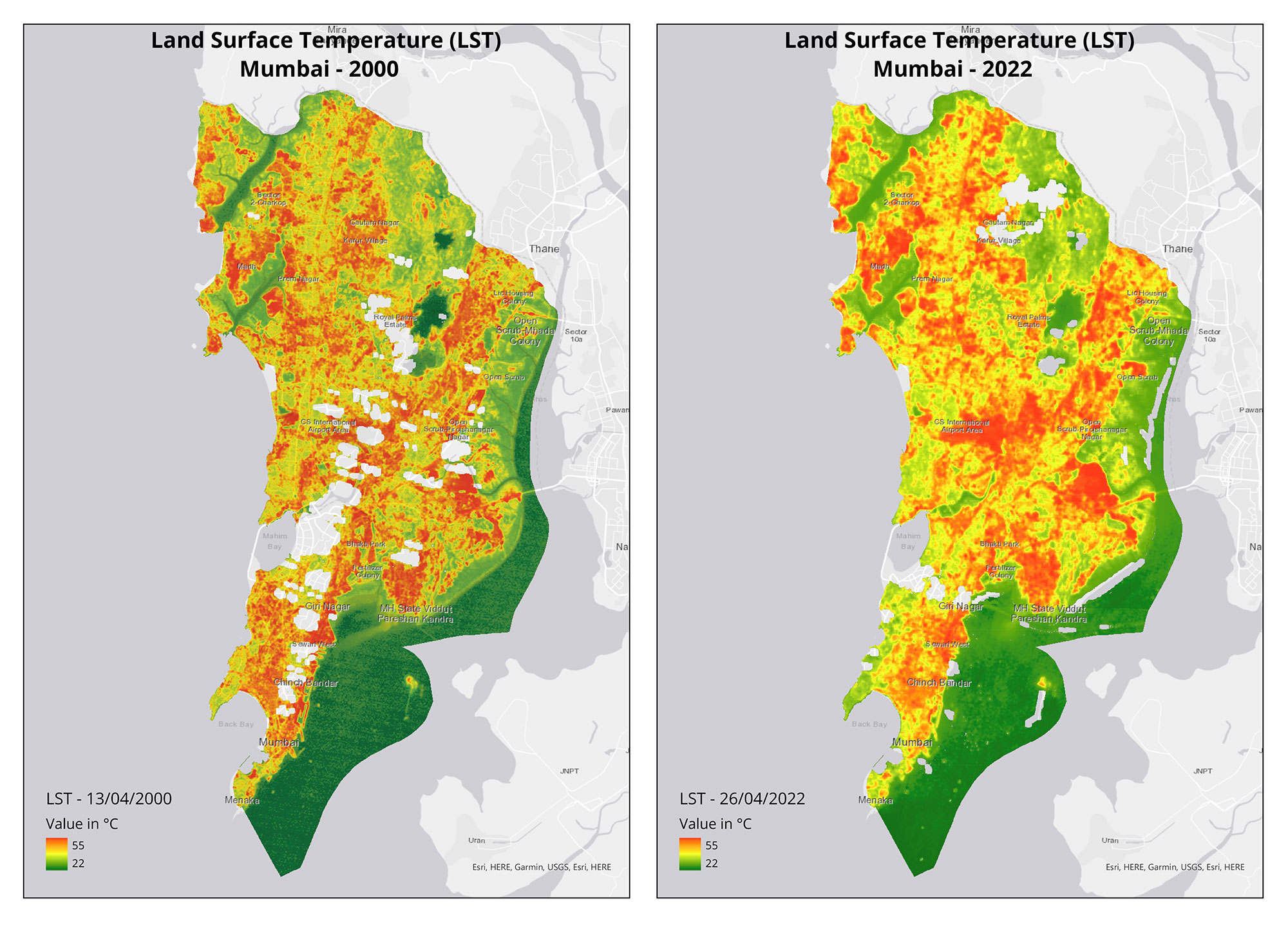
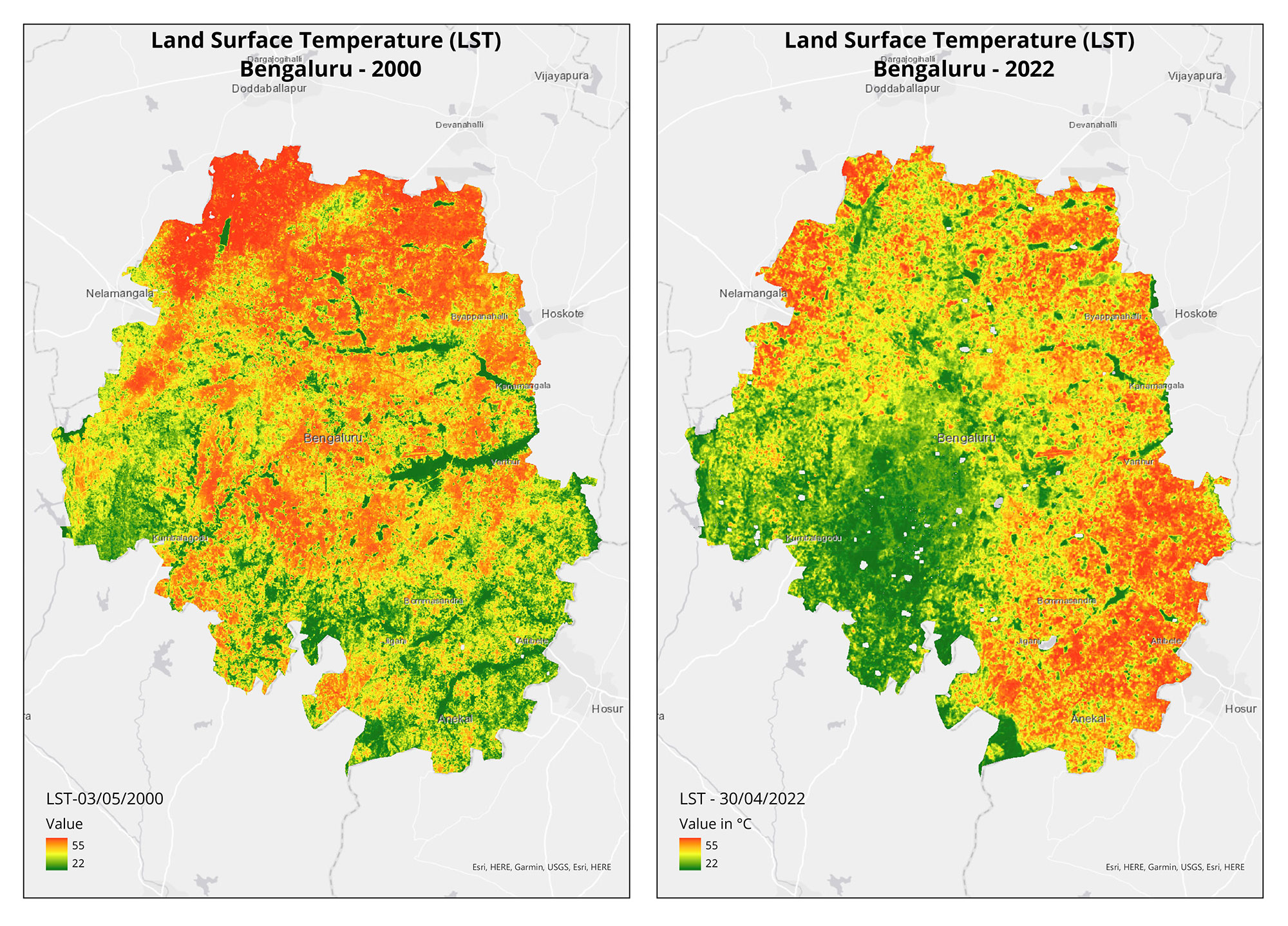
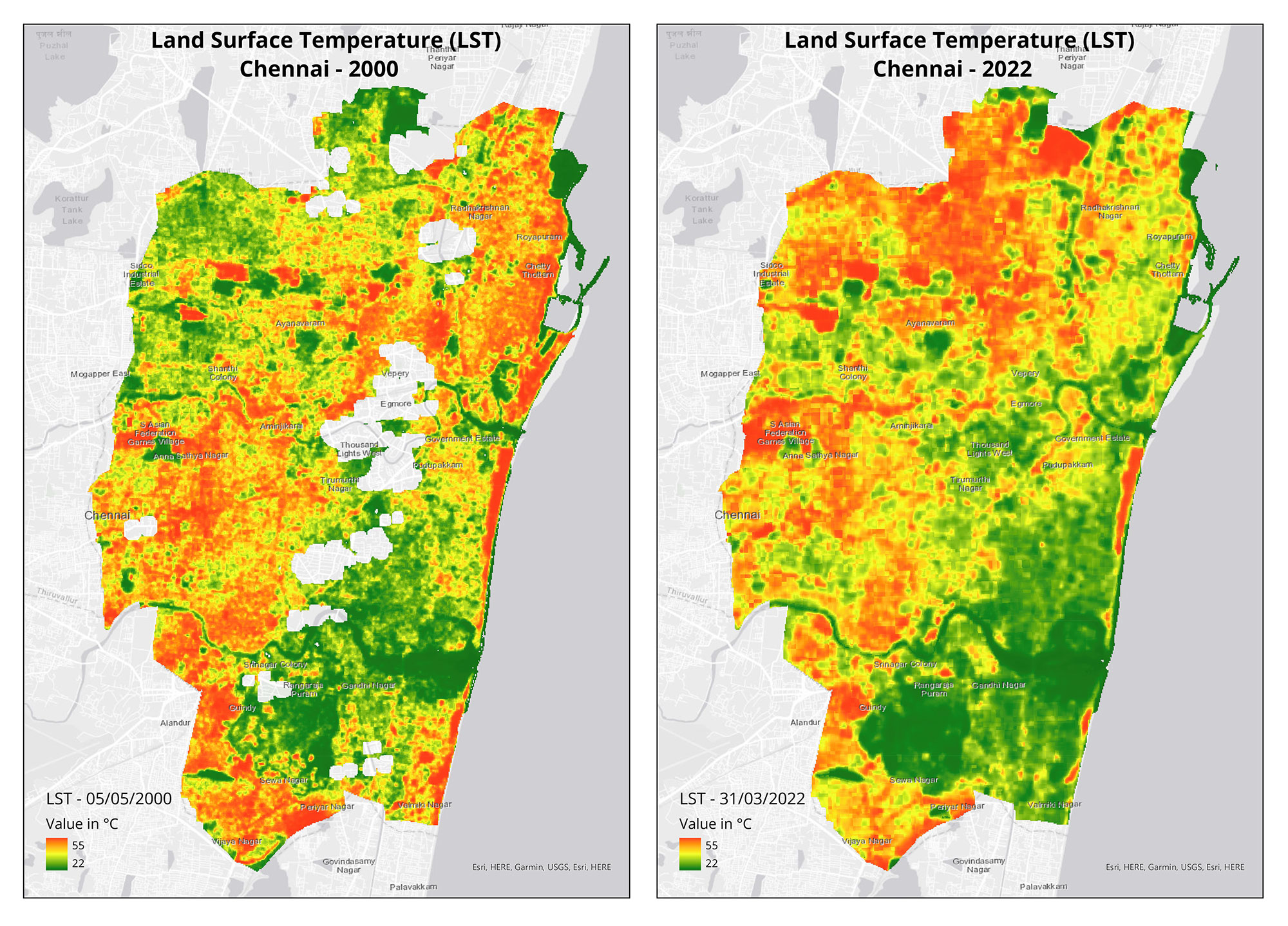
Through the summer, from April till July, we produced 21 maps for 10 stories as part of our collaboration with Mongabay-India to use cartography to broaden conservation communication for environmental journalism. August marked the completion of our two-year commitment with them. Read more the stories we have worked on together here and explore our blog-posts for the process of visualising them.
In August and September, we worked on cartography for 'Fish Curry and Rice' - a book detailing Goa's ecology and environment. Written and compiled by the Goa Foundation, it was first published in 1993, and is currently being updated for republication. As the cartographers, our goal for this project is to provide a spatial view of Goa's environmental landscape and create meaningful visuals for readers. We created over 20 outputs for publication- with revisions in October and December.
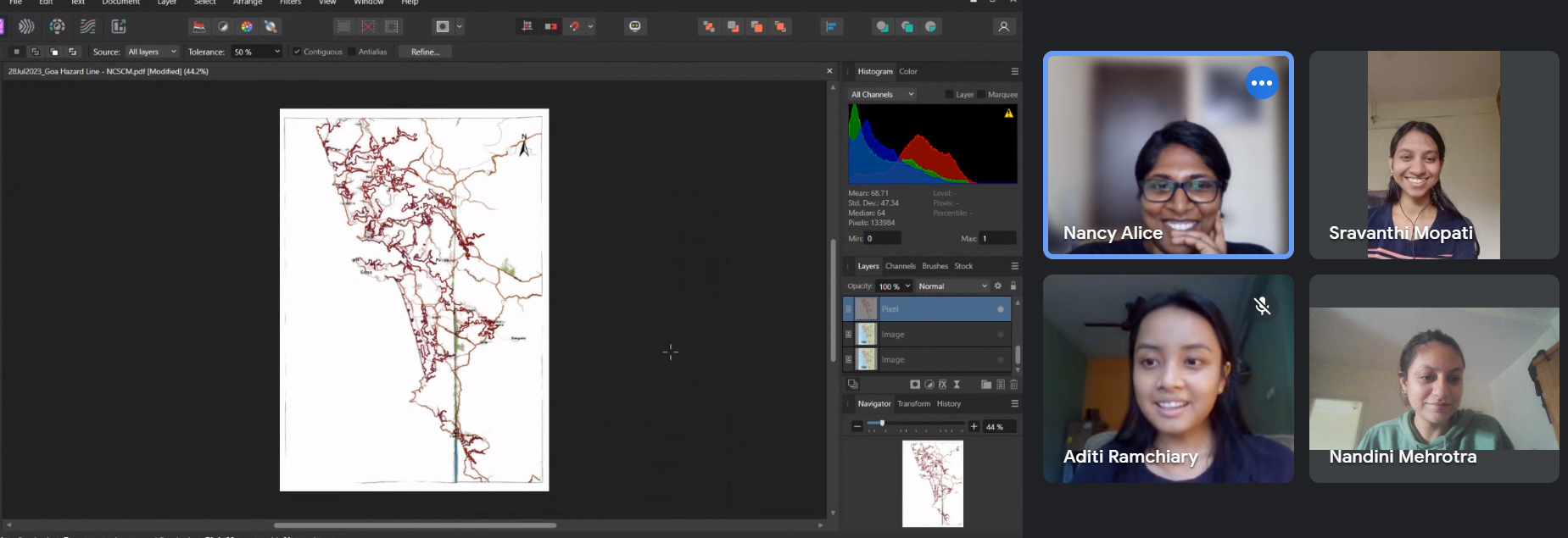
Screengrab from an internal capacity building workshop.
In September, we conducted the second phase of our internal workshop, focusing on the effective utilisation of vector design tools for cartography. During the same month, we had a meeting with WWF-India in-person in Goa to explore collaboration opportunities based on our joint efforts earlier in the year.
Also in September, we were profiled to be part of a climate report 'Our Uncommon Future,' created by Dasra and the Observer Research Foundation. The report lists us alongside fellow CSOs championing for creative climate solutions through collaborative, multi-stakeholder methods.
In October, we extended our support to citizens in Assagao on using free and open-source tools to document the forests around them. Simultaneously, we marked the beginning of the final phase of our report on the use of drones for conservation in India, by seeking reviews and feedback from the interviewees.
A special photo exhibit showcasing Shashank’s work in Ladakh was featured as part of the GDN Conference 2023 by the Global Development Network in Quito, Ecuador, during the first week of November. This exhibit, curated by Supriya Roychoudhury and TfW offers a glimpse of his work in this incredible landscape.

Aerial view of mangroves in Goa.
We have been selected as exhibitors and grantees for Science Gallery Bangalore’s exhibit on Carbon. We began work on the exhibit in the monsoon,continuing to refine our outputs through October and November. Our exhibit revolves around remote sensing methods to estimate carbon sequestered by mangrove ecosystems. We have compiled research and methods conducted over the last two years combining drone and satellite data. For this exhibit, we have also collaborated with visual artists who have interpreted our scientific outputs and analysis through multimedia. The exhibit will be open for the public soon in Bangalore and will also feature a website with digital material.

Aditi Ramchiary at her farewell. Picture courtesy of Nandini Mehrotra.
In November we bid a bittersweet farewell to our core-team member, Aditi Ramchiary, as she embarks on her journey towards an academic career. In her time with us, Aditi had numerous firsts and achievements. She skillfully blended her artistic and technical abilities, resulting in a distinctive aesthetic that made her a highly effective cartographer. In her parting blog, she talks about her experience with TfW which was also her very first job.
In December, we had exciting changes in our core-team. We welcomed Ishan Nangia, who will contribute to computer vision analysis in various projects. Ishan is a coder and a diver and is presently working with us on using computer vision to aid restoration planning. We also welcomed Dr. Madhura Niphadkar as an advisor to the same project.

TfW in discussion with the Asian Flying Labs. Picture courtesy of Anuj Pradhan.
At the beginning of December, our team travelled to attend conferences. In Delhi, we partook in the WeRobotics hosted Asia Retreat for Flying Labs, representing our work in conservation drone technology as co-leads of India Flying Labs. Simultaneously, Nandini Mehrotra, attended Ecological Restoration Alliance’s Restoring Natural Ecologies 2023 retreat in Panchgani, Maharashtra.

Identifying species from aerial footage as part of the workshop on restoration in the Western Ghats.
Mid-December, we conducted a day-long meeting cum workshop to make progress on the restoration project in the Western Ghats. Our team examined samples of our field data with Alex and Cristina- our partners on the ground. We were joined virtually by remote sensing expert Dr. Madhura Niphadkar and Dr. Kartik Teegalapalli, an expert in forest recovery. Based on our discussion on potential methodologies, we are currently testing a combination of computer-vision aided analysis of UAV footage along with satellite data and analysis, based on the input and on-ground expertise that Alex and Cristina provided.
We also began work on a new project with the Sciurid Lab of IISER Tirupati. In a virtual meeting, Dr. Nandini Rajamani and Harsha Kumar talked our team through the research that the lab is currently focusing on, and helped us understand more about the species they work with. We then explored avenues of research and the possibilities of using a combination of computer vision and spatial analysis to further explore data collected through our previous field work with the lab in 2022.

Last team-call of 2023.
As the year drew to a close, we concluded with a team call, summarising the events of the year, sharing personal and work reflections.